Blogpost 10. Januar 2018
Was ist Machine Learning?

Hinter Machine Learning – zu deutsch Maschinelles Lernen – verbirgt sich die Idee, dass ein künstliches System Zusammenhänge aus seiner Umwelt lernt und das erworbene Wissen für neue Ereignisse in seiner Umwelt verallgemeinern kann. Lernende Algorithmen lassen sich je nachdem, wie sie lernen und wofür sie eingesetzt werden sollen, in verschiedenen Kategorien einteilen.
Was ist Supervised Learning?
Beim Supervised Learning soll der Algorithmus ein bestimmtes Ereignis vorhersagen, zum Beispiel ob ein Kunde das Produkt aufgrund seiner Eigenschaften kauft oder nicht.
Um diese Vorhersage zu treffen, muss der Algorithmus zunächst lernen, welche Produkteigenschaften die Kaufentscheidung stark beeinflussen und welche nicht. Dafür stehen ihm so genannte Trainingsdaten zur Verfügung. Diese enthalten eine Sammlung aus Input-Target-Paaren: ein Produkt mit seinen Eigenschaften (Input) sowie die dazugehörige Kaufentscheidung (Target).
Aus dieser Sammlung lernt der Algorithmus, welche Produkteigenschaften zu welcher Kaufreaktion führen. Dieses Wissen kann er dann für neue Inputdaten für Vorhersagen nutzen. Häufig überprüft man die Qualität dieser Vorhersagen zusätzlich auf so genannten Testdaten, die ebenfalls Inputs und Targets beinhalten. Der Algorithmus trifft dann seine Vorhersagen für die einzelnen Produkte, ohne die dazugehörige Kaufentscheidung zu kennen. Anschließend ermittelt dann eine Gütefunktion, wie gut die Vorhersagen im Vergleich zu den korrekten Targets ausgefallen sind.

Wie funktioniert Supervised Learning?
Das lässt sich am besten anhand eines Beispiels verstehen:
Im Projekt VAMINAP zum Beispiel verwenden wir Methoden aus dem Supervised Learning, um vorherzusagen, ob sich im geklärten Wasser noch Schadstoffe befinden. Dazu verwenden wir künstliche neuronale Netze, um vorherzusagen, ob und in welcher Konzentration Schadstoffe im geklärten Wasser zu finden sind.
Die Trainingsdaten wurden uns vom Laser-Laboratorium Göttingen e. V. zur Verfügung gestellt und beinhalten als Target die Schadstoffkonzentration einer Wasserprobe sowie als Input das Ramanspektrum dieser Probe. Anhand vieler Input-Target-Paare lernt das Netz den Zusammenhang zwischen Ramanspektren und Schadstoffkonzentrationen.
Doch wie schafft es das? Um das zu beantworten, muss man einen Blick ins Innere des Netzes werfen.
Wie funktioniert ein künstliches neuronales Netz?
Ein künstliches neuronales Netz ist im Grunde nur ein abstraktes, mathematisches Modell, das den Informationsfluss seines biologischen Vorbilds vereinfacht darstellt:
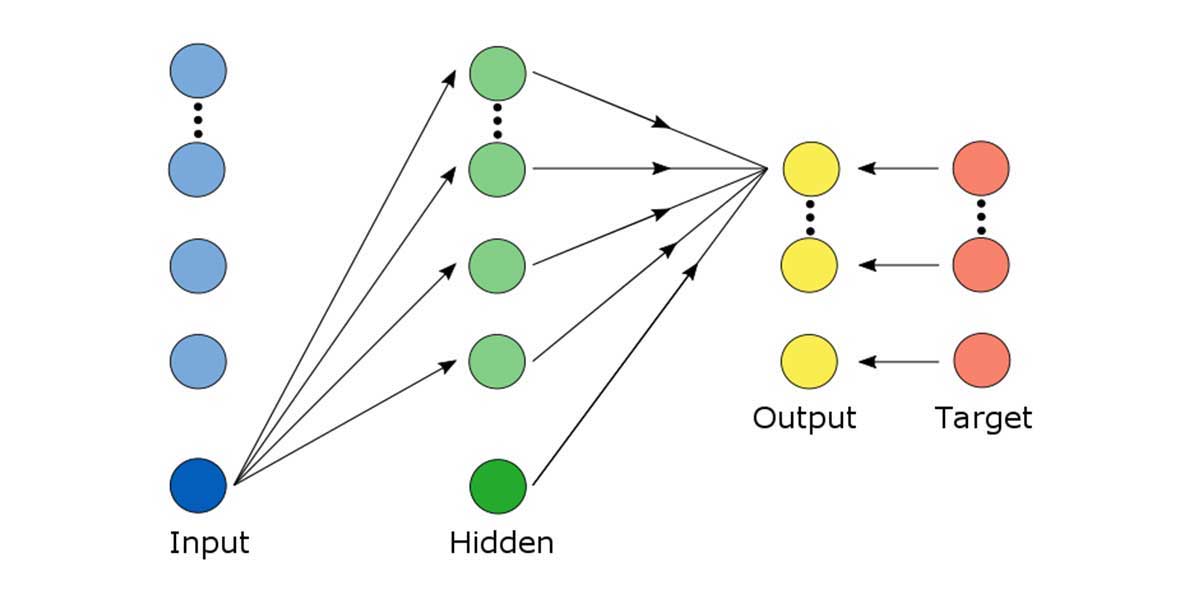
Häufig besteht es aus mehreren, aufeinanderfolgenden Neuronenschichten: Inputneuronen (blau), beliebig viele Schichten versteckte Neuronen (grün) und Outputneuronen (gelb). Jedes Neuron hat einen Wert, der sich aus den vorangegangen Neuronen berechnen lässt, die mit ihm verbunden sind. Die Neuronen zweier Schichten können dabei vollständig miteinander vernetzt sein. Leitet ein Neuron seine Information an ein anderes weiter, so wird die Stärke dieser Informationsübertragung durch einen anpassbaren Parameter gewichtet.
Lernen beschreibt nun den Vorgang, den Informationsfluss im Netz durch die Parameter so zu kanalisieren, dass der Fehler zwischen den berechneten Outputs (gelb) und den Targets (rot) minimal wird. Der Fehler wird dabei mit der so genannten „loss“ oder auch „objective function“ ermittelt. Das Lernen beinhaltet viele Zyklen und endet erst dann, wenn sich der Fehler auf den Trainingsdaten kaum noch verändert oder die Güte auf den Testdaten sinkt. Ist letzteres der Fall, hat das Netz Zusammenhänge gelernt, die nur für die Trainingsdaten typisch sind und nicht mehr im Allgemeinen gelten.
Lernen nur künstliche neuronale Netze auf diese Art?
Nein, sie sind hier als Beispiel einer größeren Gruppe lernender Algorithmen genannt. Parametrisierte Algorithmen werden sehr häufig im Supervised Learning verwendet und lernen alle, indem sie Parameter ihrer mathematischen Struktur finden, welche den Fehler auf den Trainingsdaten minimieren.
Was ist dagegen Unsupervised Learning?
Beim Unsupervised Learning stehen dem Algorithmus beim Lernen keine Targets zur Verfügung. Er kann daher seine Vorhersagen nicht mit korrekten Zielwerten vergleichen und muss quasi die Muster ausschließlich aus den Inputdaten lernen. Häufige Anwendungsgebiete sind zum Beispiel die Clusteranalyse oder die Dimensionsreduktion mittels Hauptkomponentenanalyse.
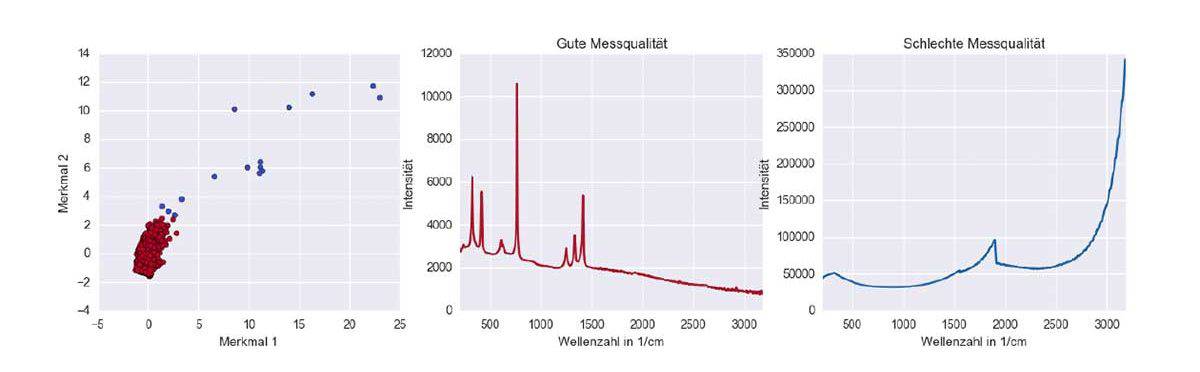
Das Beispiel VAMINAP schafft hier Klarheit: Hier müssen wir qualitativ gute von qualitativ schlechten Spektren unterscheiden. So können Nebeneffekte, Rauschen und Messfehler die Qualität unserer Daten und damit den Lernerfolg stark beeinflussen. Um weiterhin gute Vorhersagen für die Schadstoffkonzentration im Wasser treffen zu können, möchten wir daher die Daten schlechter Qualität aufspüren und ausschließen.
Hierfür eignet sich beispielsweise die Clusteranalyse mit DBSCAN. Dafür werden aus den Spektren Merkmale extrahiert, welche die Datenqualität treffend beschreiben können. Diese Merkmale spannen einen so genannten Merkmalsraum auf, in welchem nun die Daten guter Qualität eine große Gruppe bzw. ein Cluster bilden. Die Daten schlechter Qualität hingegen unterscheiden sich stark von dieser Gruppe und streuen in den Merkmalsraum hinein. Der DBSCAN-Algorithmus ist in der Lage, dieses Rauschen vom eigentlichen Cluster zu unterscheiden und zu kennzeichnen. Wie man sieht, gelingt es dem lernenden Algorithmus sehr gut, Daten hinsichtlich ihrer Qualität zu unterscheiden:
Wie beeinflussen die Daten den Lernerfolg?
Die Daten selbst haben einen entscheidenden Einfluss auf den Lern- und damit auch Vorhersageerfolg. Denn hinter Machine Learning verstecken sich mathematische Modelle, die zu den Daten und zur Aufgabenstellung passen müssen.
Einen lernenden Algorithmus zum Erfolg zu führen, bedeutet aus diesem Grund, die Daten entsprechend der Annahmen zu analysieren und aufzubereiten. Sind zu wenig Daten zum Lernen vorhanden oder weisen diese eine schlechte Qualität auf, so kann das natürliche Muster der zugrunde liegenden Prozesse nicht gelernt werden. Das macht Machine Learning zum perfekten Partner für Big Data. Durch eine große Menge an qualitativ guten Daten erhoffen wir uns, das gesamte Spektrum aller Erscheinungsformen der Inputs zu erfassen und für exakte Vorhersagen zu nutzen.
Wo finde ich Machine Learning im Alltag?
Lernende Algorithmen sind bereits allgegenwärtig: Morgens steigen wir ins Auto, entsperren unser Smartphone mit unserer Stimme und lassen uns per App durch die Rush Hour führen. Auf der Arbeit suchen wir nach einem Fachartikel und lassen ihn wohlmöglich direkt online übersetzen. Den Abend lassen wir mit einem Film aus unserer Lieblings-Online-Videothek ausklingen. Die Empfehlungen, die wir erhalten, sind dabei nicht zufällig. Sie basieren auf den Vorhersagen lernenden Algorithmen, welche in den Daten vieler Nutzer Zusammenhänge und Muster gefunden haben.
Machine Learning liegt im Trend und die Entwicklung schreitet rasant voran. So sind selbstfahrende Autos bereits keine Zukunftsmusik mehr. Auch wir hoffen, mit VAMINAP durch das Aufspüren von Schadstoffen im Wasser einen wichtigen Beitrag für die Welt von morgen leisten zu können.


